The Fine Print Is Anything but Sticky: A New 25-Year Corpus of Digital Contracts
Posted:
Time to read:
3 Minutes
The terms of use (‘TOUs’) of platforms like TikTok, Facebook, Venmo, and Uber are among the most prolific contracts in human history. They bind billions of users and cover a vast range of online interactions. Yet almost no one reads them. Until now, almost no one has been able to study how they change over time.
That gap is not for lack of interest. A rich literature on contract change has documented a striking tendency toward “stickiness.” That is, contracts resist change, even when economic conditions favour revision. Sovereign bonds, merger agreements, and other negotiated instruments tend to recycle boilerplate and evolve slowly. A primary obstacle to research on contract change has been the scarcity of data. Digital contracts are ephemeral; they are revised unilaterally, frequently, and without fanfare. Old versions vanish from the live web. Building a clean, version-by-version record across many platforms and many years is laborious, which is why it has rarely been done.
In our article, forthcoming in the Journal of Empirical Legal Studies, we introduce the Longitudinal Digital Terms Corpus (LDT Corpus) to close that gap. The corpus is a hand-collected time series of 861 TOUs from fifty prominent platforms from 1999 to 2025, roughly 6.87 million tokens of contract text governing more than 25 billion user accounts. We reconstruct each platform’s full history from the Wayback Machine and website archives. We then analyse the texts with a toolkit that combines corpus linguistics with recent advances in natural language processing.
Figure 1: Longitudinal Coverage by Platform. Horizontal blocks represent the presence of each platform in the LDT Corpus during the TOU time series, which runs from 1999 to 2025. Colors distinguish platforms for visual clarity and do not encode any variable.
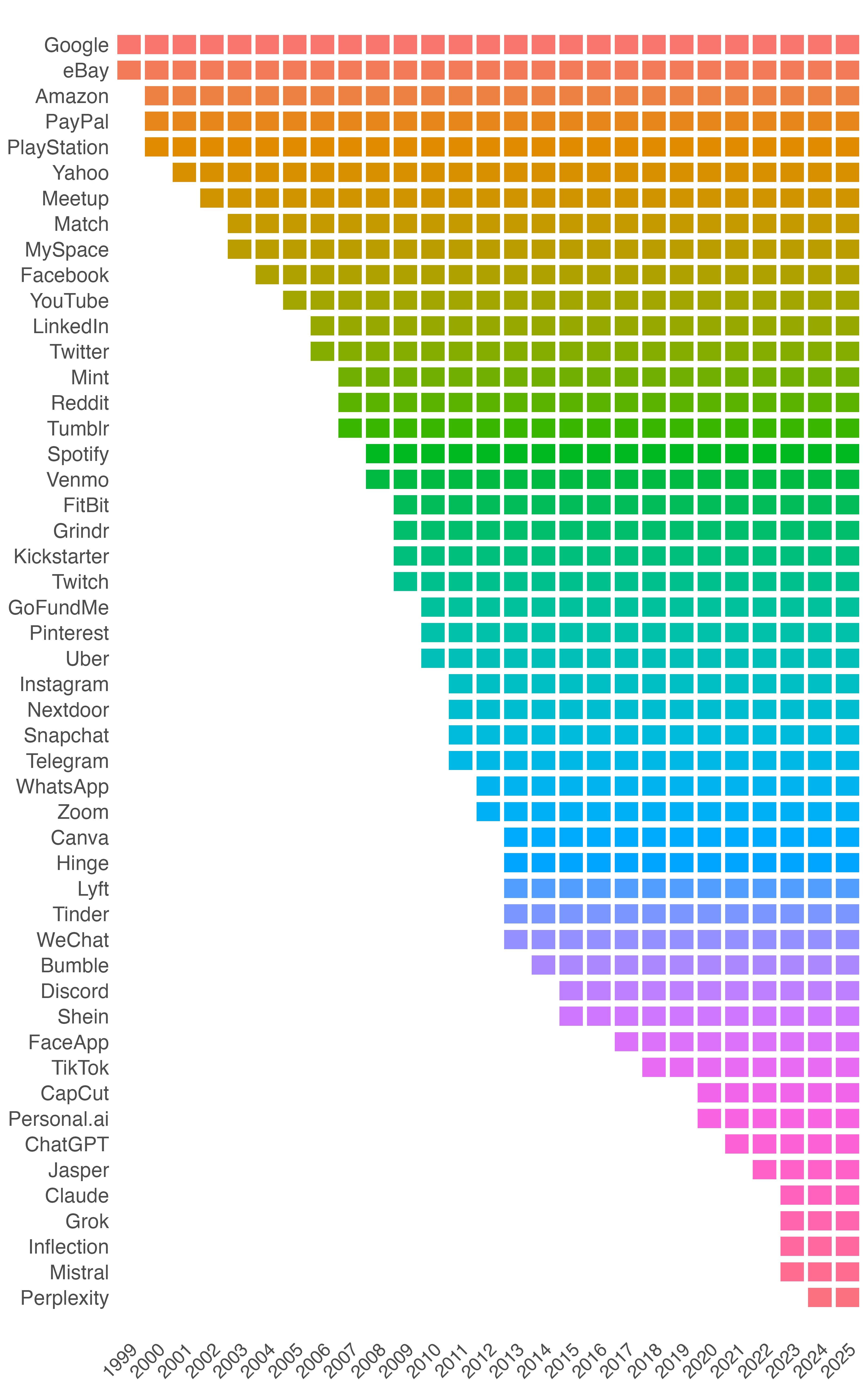
Figure 1: Longitudinal Coverage by Platform. Horizontal blocks represent the presence of each platform in the LDT Corpus during the TOU time series, which runs from 1999 to 2025. Colors distinguish platforms for visual clarity and do not encode any variable.
Three findings stand out.
First, digital TOUs are remarkably plastic. The TOUs in our corpus update frequently—1.42 times per year on average—and many of those revisions are extensive rather than cosmetic. Using sentence-level text embeddings, we measure how much of each contract is copied, added, or deleted between successive versions. While some updates carry over nearly all of the prior text, others involve major rewrites. This plasticity stands in apparent contrast to the stickiness documented elsewhere in the contracts literature. Our finding suggests that unilateral, low-friction modification produces a very different dynamic of change.
Figure 2: Absolute number of added sentences over time. Points in the lines indicate TOU updates for the selected platforms.
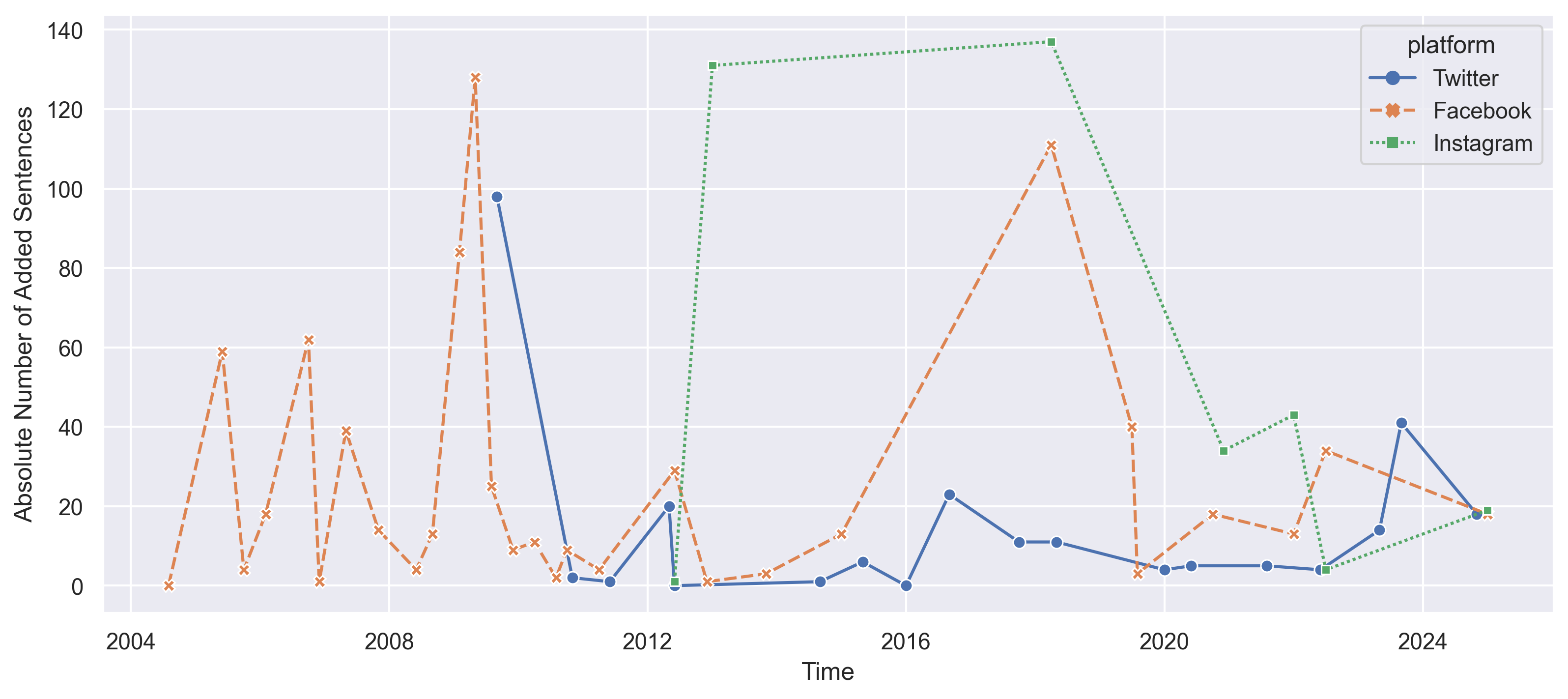
Figure 2: Absolute number of added sentences over time. Points in the lines indicate TOU updates for the selected platforms.
Second, the burden of reading TOUs is higher over time. TOUs have grown dramatically longer while holding their linguistic complexity roughly constant. The average TOU expanded from about 2,086 words in 1999 to 10,562 in 2025—more than fivefold—and the trend is nearly universal across platforms. Google’s first terms, dated September 1999, ran under 900 words. TOUs today are much longer, yet the language itself stays consistently difficult over time rather than getting steadily worse. We combine length and four complexity indicators—verbal density, dependency distance, centre-embedding, and a traditional readability formula—into a single measure of the “linguistic burden” of reading these contracts. The rising burden is mainly driven by length, not complexity.
Figure 3: Composite z-score of the “linguistic burden” of TOUs over time.
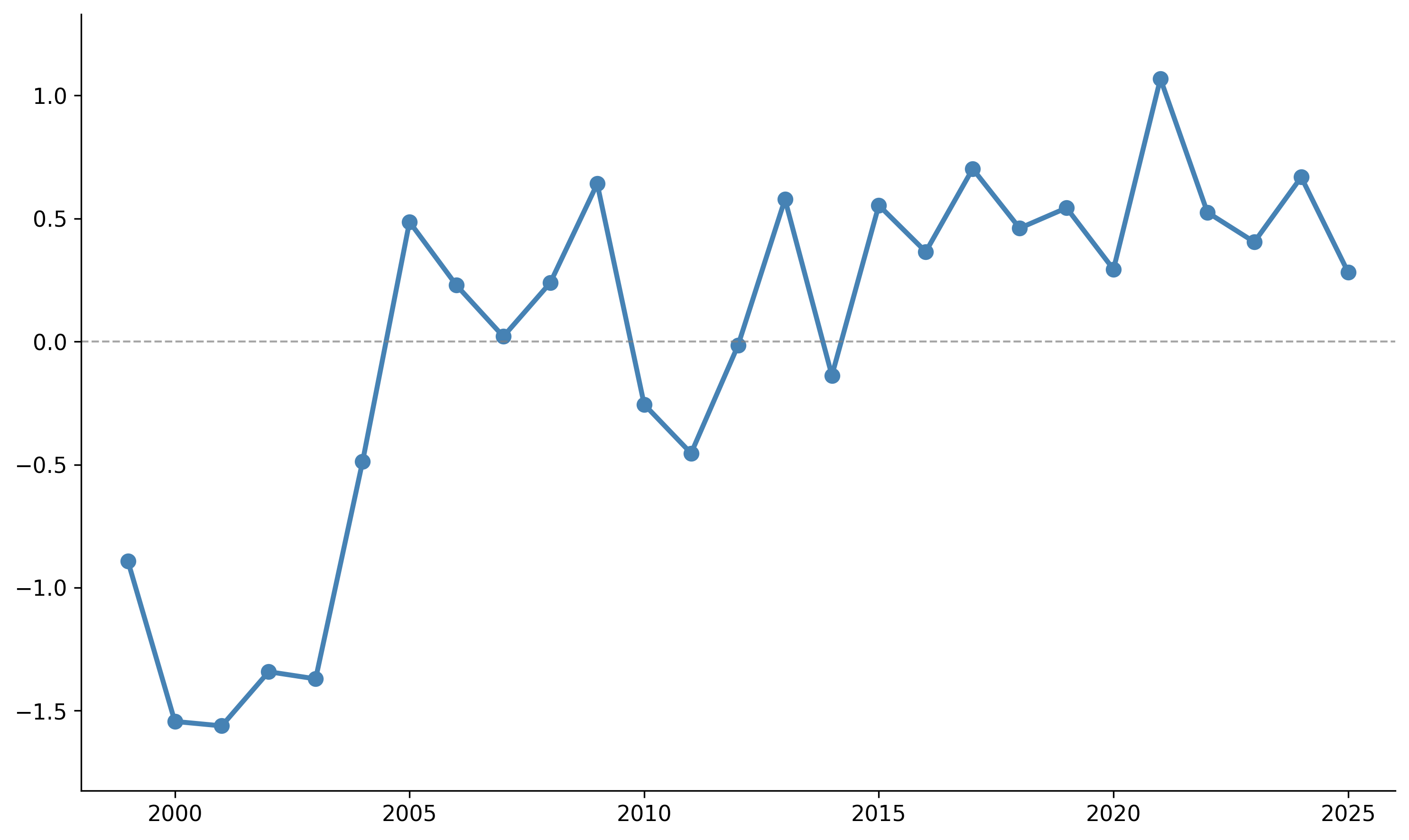
Figure 3: Composite z-score of the “linguistic burden” of TOUs over time.
Third, corporate affiliation leaves a textual fingerprint. By scoring the similarity of each platform’s terms against the rest of the corpus, we observe convergences among affiliated platforms. The Facebook and Instagram terms grow markedly more alike after Facebook’s 2012 acquisition. WhatsApp converges as well, if less sharply. We find similar patterns in fintech (eBay, PayPal, and Venmo) and among dating apps (Match, Hinge, and Tinder). Similarity tracks with changes in corporate control, though we are careful to treat it as correlational at this stage.
Figure 4: Proportion of similar sentences in TOUs over time between Facebook and other platforms. Vertical lines indicate an update of the Facebook TOU. Lighter gray lines show the similarity scores for all other contracts in the LDT Corpus.
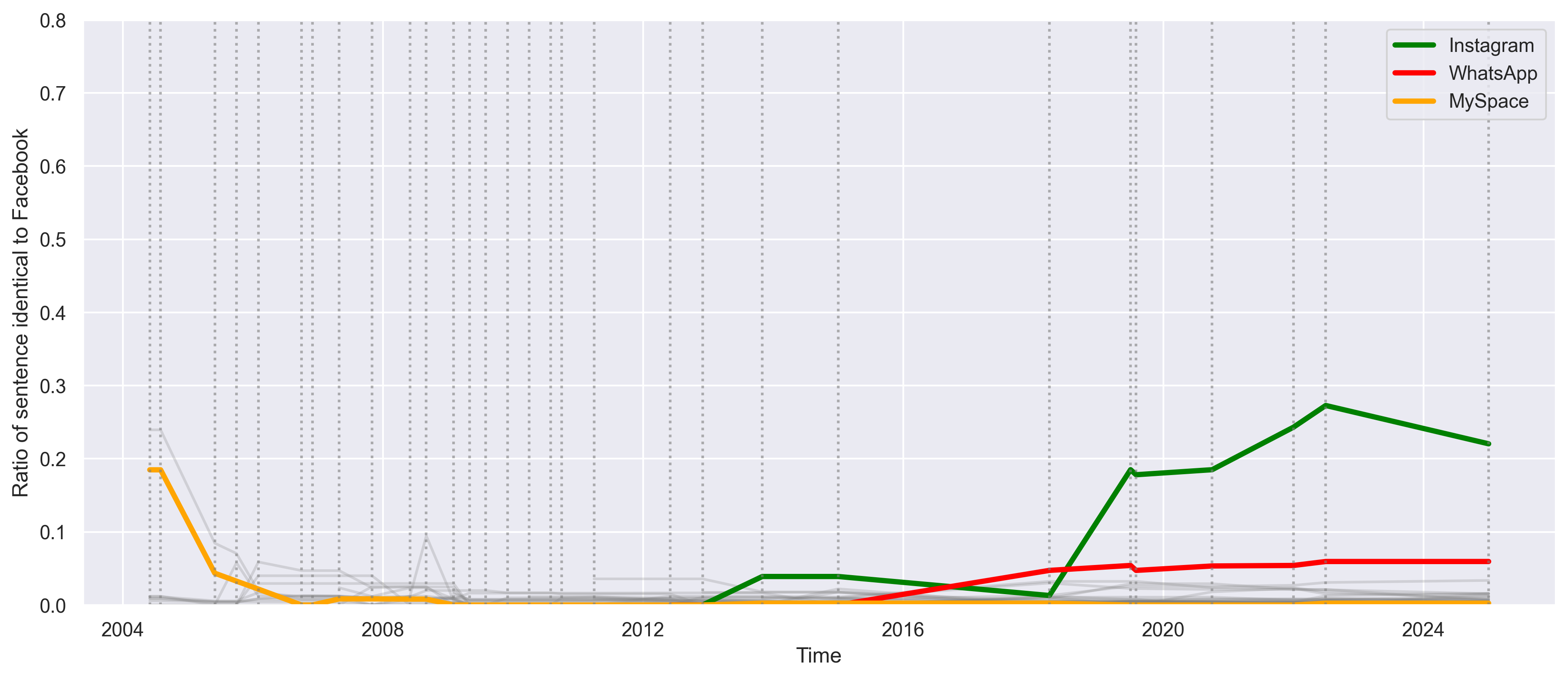
Figure 4: Proportion of similar sentences in TOUs over time between Facebook and other platforms. Vertical lines indicate an update of the Facebook TOU. Lighter gray lines show the similarity scores for all other contracts in the LDT Corpus.
Taken together, these results offer a first systematic look at how a vast and consequential category of contracts actually evolves. They also open questions the LDT Corpus is well suited to pursue. Because the series covers more than two decades, the LDT Corpus supports event-study approaches to how TOUs respond to judicial decisions, regulatory pressure, and external shocks. The corpus can also surface patterns of change beyond plasticity and affiliation-driven convergence. Our methods have complementary applications, too: the embedding-based approach we use to track change and similarity can be applied to other domains of legal text analysis.
The contracts almost no one reads turn out to have a great deal to say about how private ordering works online. By making the LDT Corpus public, we hope to make that conversation easier to join.
The authors’ article, “Introducing a New Longitudinal Corpus of Digital Contracts, 1999–2025,” is forthcoming in the Journal of Empirical Legal Studies and can be accessed here. The LDT Corpus is available at github.com/LegalTextLab/LDT.
Tim R Samples is Professor of Legal Studies at the Terry College of Business, University of Georgia.
Katherine Ireland is Assistant Director at the Ivester Institute for Business Analytics and Insights, Terry College of Business, University of Georgia.
Kaspar Beelen is Technical Lead at the Digital Humanities Research Hub, School of Advanced Study, University of London.
OBLB categories:
Commercial Law
OBLB types:
Research
Share: