Remember your last online purchase? Chances are, the price you paid was not set by humans but rather by a software algorithm. Already in 2015, more than a third of the vendors on Amazon.com had automated pricing, and the share has certainly risen since then: with the growth of a repricing software industry that supplies turnkey pricing systems, even the smallest vendors can now afford algorithmic pricing.
Unlike the traditional revenue management systems, long in use by such businesses as airlines and hotels, in which the programmer remains effectively in charge of the strategic choices, the pricing programs that are now emerging are much more ‘autonomous’. These new algorithms adopt the same logic as the Artificial Intelligence (AI) programs that have recently attained superhuman performances in complex strategic environments such as the game of Go or chess. That is, the algorithm is instructed by the programmer only about the aim of the exercise – winning the game or generating the highest possible profit. It is not told specifically how to play the game. It instead learns from experience. In a training phase the algorithm actively experiments with alternative strategies by playing against clones in simulated environments, more frequently adopting the strategies that perform best. In this learning process, the algorithm requires little or no external guidance. Once the learning is completed, the algorithm is put to work.
Our paper shows that, from an antitrust perspective, the concern is that these autonomous pricing algorithms may independently discover that if they are to make the highest possible profit they should avoid price wars. That is, they may learn to collude, even if they have not been specifically instructed to do so, and even if they do not communicate with one another. This is a problem. First, ‘good performance’ from the sellers’ perspective, for instance high prices, is bad for consumers and for economic efficiency. Second, in most countries (including EU Member States and the United States) such ‘tacit’ collusion, not relying on explicit intent and communication, is not currently treated as illegal, on the grounds that it is unlikely to occur among human agents and that, even if it did occur, it would be next to impossible to detect. The pre-AI conventional wisdom was that aggressive antitrust enforcement would be likely to produce many false positives (i.e. condemning innocent conduct), while tolerant policy would result in relatively few false negatives (i.e. excusing anticompetitive conduct). With the advent of AI pricing, however, the concern is that the balance between the two types of error might be altered. Though no real-world evidence of autonomous algorithmic collusion has been produced so far, antitrust agencies are actively debating the problem.
Commentators such as Ezrachi and Stucke argue that AI algorithms already outperform humans at many tasks, and there seems to be no reason why pricing should be any different. They also refer to a computer science literature that has documented the emergence of some degree of uncompetitively high prices in simulations where independent pricing algorithms interact repeatedly. Scholars such as Harrington are developing paths towards making AI collusion unlawful.
Skeptics, for instance Schwalbe, counter that these simulations do not use the canonical model of collusion, thus failing to represent actual markets. Furthermore, the degree of anti-competitive pricing appears to be limited, and in any case high prices as such do not necessarily indicate collusion, which instead must involve some kind of reward-punishment scheme to coordinate firms’ behavior. According to the skeptics, achieving genuine collusion without communication is a daunting task not only for humans but even for the smartest AI programs, especially when the economic environment is stochastic. Whatever over-pricing is found in the simulations, it could be due to the algorithms' failure to learn the competitive equilibrium. If this were so, then there would be little reason to worry, given that the problem will presumably fade away as artificial intelligence develops further.
To inform this policy debate, in our recent paper we constructed AI pricing agents and let them interact repeatedly in controlled environments that reproduce economists’ canonical model of collusion, i.e. a repeated pricing game with simultaneous moves and full price flexibility. Our findings suggest that in this framework even relatively simple pricing algorithms systematically learn to play sophisticated collusive strategies. The strategies mete out punishments that are proportional to the extent of the deviations and are finite in duration, with a gradual return to the pre-deviation prices.
The following figure illustrates the punishment strategies that the algorithms autonomously learn to play. Starting from the (collusive) prices on which the algorithms have converged (the grey dotted line), we override one algorithm’s choice (the red line), forcing it to deviate downward to the competitive or Nash price (the orange dotted line) for one period. The other algorithm (the blue line) keeps playing as prescribed by the strategy it has learned. After this exogenous deviation in period, both algorithms regain control of the pricing.
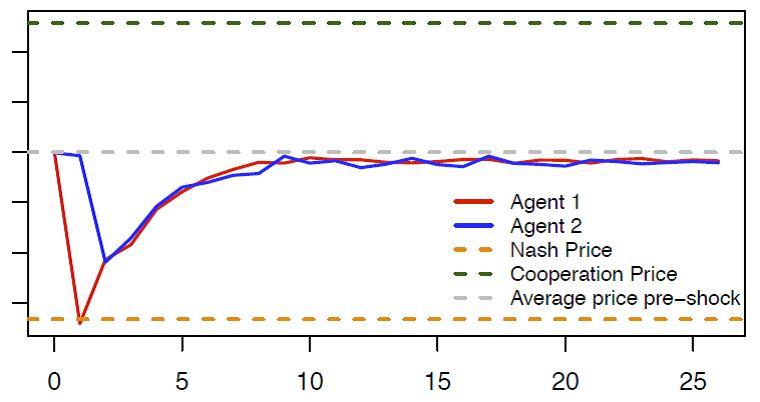
Figure 1: Price responses to deviating price cut.
The blue and red lines show the price dynamic over time of two autonomous pricing algorithms (agents) when the red algorithm deviates from the collusive price in the first period.
The graph shows the price path in the subsequent periods. Clearly, the deviation is punished immediately (the blue line price drops immediately after the deviation of the red line), making the deviation unprofitable. However, the punishment is not as harsh as it could be (for instance, reversion to the competitive price), and it is only temporary: afterwards the algorithms gradually return to their pre-deviation prices.
What is particularly noteworthy is the behavior of the deviating algorithm. Plainly, it is responding not only to the rival but also to its own action. (If it responded only to the rival, there would be no reason to cut the price in period, as the rival has charged the collusive price in period.) This kind of self-reactive behavior is a distinctive sign of genuine collusion, and it would be difficult to explain otherwise.
The collusion that we find is typically partial: the algorithms do not converge to the monopoly price but a somewhat lower one. However, we show that the propensity to collude is stubborn: substantial collusion continues to prevail even when the active firms are three or four in number, when they are asymmetric, and when they operate in a stochastic environment. The experimental literature with human subjects, by contrast, has consistently found that they are practically unable to coordinate without explicit communication save in the simplest case with two symmetric agents and no uncertainty.
Most worryingly, algorithms leave no trace of concerted action: they learn to collude by trial and error, with no prior knowledge of the environment in which they operate, without communicating with one another, and without being specifically designed or instructed to collude. This poses a real challenge for competition policy. While more research is needed before considering policy moves, the antitrust agencies’ call for attention would appear to be well grounded.
Emilio Calvano is Senior Assistant Professor at the Department of Economics, University of Bologna and TSE Associate Faculty at the Toulouse School of Economics.
Giacomo Calzolari is Professor of Economics at the European University Institute and at the Department of Statistical Sciences ‘Paolo Fortunati’, University of Bologna, TSE Associate Faculty at the Toulouse School of Economics, and Research Fellow at the Centre for Economic Policy Research.
Vincenzo Denicolò is Professor at the Department of Economics, University of Bologna and Research Fellow at the Centre for Economic Policy Research.
Sergio Pastorello is Professor at the Department of Economics, University of Bologna.
This post has been previously published by the CEPR Policy Portal.
OBLB types:
Share: